OCRの仕組み|OCRソフトの精度を決めるアルゴリズム?

この記事の目次
OCRの仕組み|OCRを実現する技術
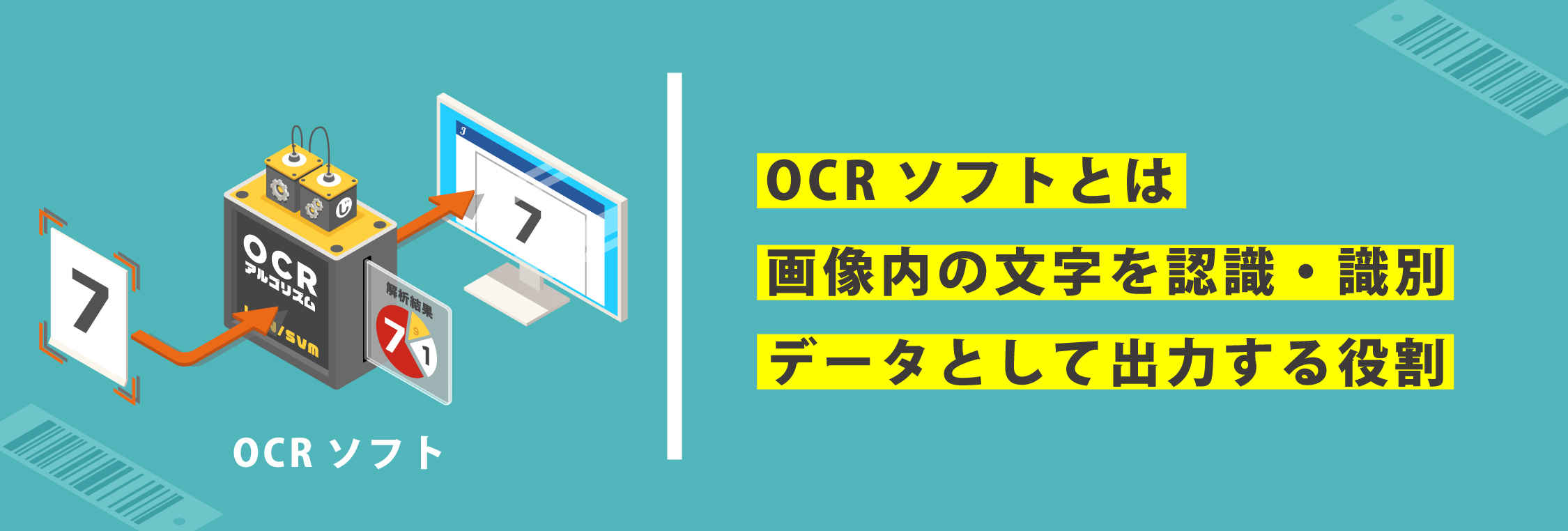
OCRを構成するハードウェアは、カメラとコンピューターを組み合わせたものです。そして、撮影された画像データに含まれる文字を識別するためのソフトウェアが必要です。OCRソフトとはOCRリーダーなどのカメラから撮影された画像内の文字を認識・識別し、パソコンなどで使えるテキストデータとして出力する役割をします。
OCRソフトの働き|3つのステップ
OCRソフトが文字を文字を識別してデータとして出力するまでに主に3つのステップがあります。
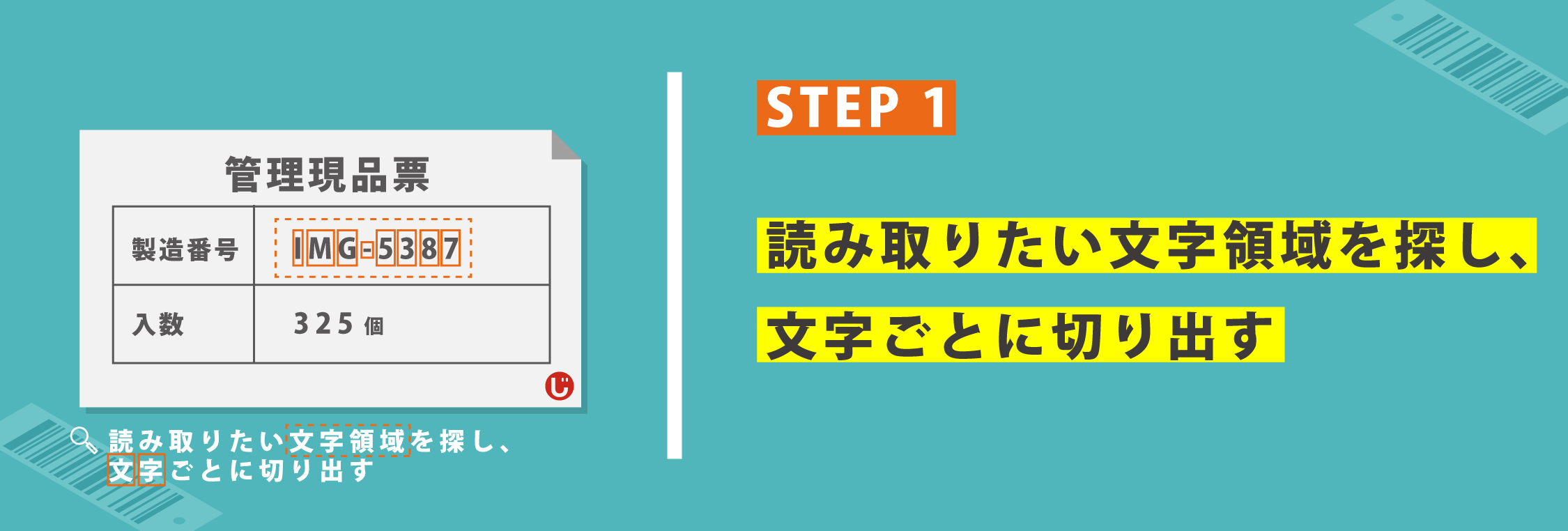
【STEP1】画像の中から画像処理を駆使して読み取り対象となる文字領域を探し出し、文字ごとに切り出しを行います。
背景のイラストや罫線など、画像内には読み取りたい文字とは全く関係ない情報が入り込んでいます。まずはその情報の中から文字領域を探し出し、1文字毎に切り出しを行います。
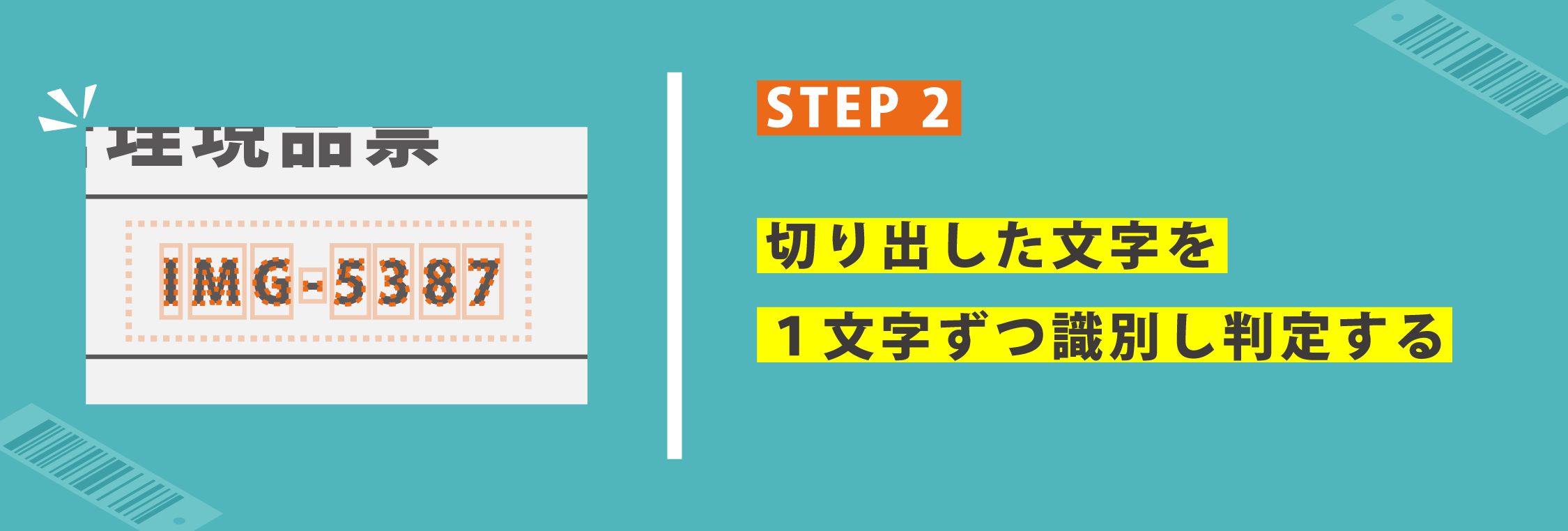
【STEP2】事前に登録されたフォントデータをもとに抽出された文字領域の中から1文字ずつ種類を識別します。

【STEP3】最後に識別した情報をテキスト・データとしてパソコンやタブレットなどデータを受けるデバイスに出力します。
OCR・文字識別のためのアルゴリズム
OCR・文字読み取りの精度には文字識別のアルゴリズムが大きく影響します。アルゴリズムとはコンピューターの計算手法のことですが、OCRではあらかじめ読み取りたい文字をデータとして機械に覚えさせておく機械学習アルゴリズムが用いられることが一般的です。OCRを可能にする機械学習アルゴリズムにはいくつかの種類がありますが、本記事ではOCRで用いられる代表的な3つのアルゴリズム、【kNN法】・【SVM法】・【ディープ・ラーニング法】を紹介します。それぞれのアルゴリズムの特徴は以下のようになります。
| kNN法 | SVM法 | ディープ・ラーニング法 | |
| 計算量 | 小さい | 大きい | 非常に大きい |
| 必要なハードウェアリソース | 小さく済む | ある程度大きい必要がある | 非常に大きなハードウェアリソースが必要 |
| 読み取り精度 | 良い ただし、印字条件の変化に弱い | 良い 印字条件の変化に強い | 良い 印字条件の変化に強い |
| 読み取り可能な書体の数 | 少数に限られる | バリエーションが多い | バリエーションが非常に多い |
OCRの前工程|はじめに読み取りたいフォントを機械学習させる

【kNN法】・【SVM法】・【ディープ・ラーニング法】は読み取りたいフォントをあらかじめ画像データとして準備し、機械学習させます。OCRリーダーで読み取りたい文字をスキャンして文字認識を行うわけですが、保存しているフォントの画像データと照合・識別したい読み取り対象の文字のことを*【未知の文字】や【未知のデータ】と表現することが一般的です。
※本記事では【未知の文字】に統一しております。
OCRの文字識別のアルゴリズムは【kNN法】・【SVM法】・【ディープ・ラーニング法】など複数ありますが、読み取りたいフォントを事前に登録させ学習させる前工程は共通して必要です。
kNN(k-Nearest Neighbor Algorithm)法|原始的な機械学習?
kNN法はk-Nearest Neighbor Algorithmの略で機械学習の中でも最も原始的な教師あり学習方法の1つです。「予め準備しておいた画像データとの距離を測定して、最も近いものをk個選択してそれらの多数決から目的とする値を求める」手法です。
仮に、読み取り可能な文字を【A】・【B】・【C】・【D】 の4個とした場合、あらかじめ撮影した画像から切り出した文字の画像(例えば、28×28ドット)をそれぞれ10枚ずつメモリーに保存しておきます。新たに入力された【未知の文字】の画像と、あらかじめ前工程で保存しておいた40(=A,B,C,D x各10)枚の画像の*距離を測定して距離が短い順に並べます。このうち、識別するために保存しておいた上位のデータの中から【未知の文字】に近いものをk個選びます。k個のうち、最も数が多かったものを文字として識別します。例えば、k=5と設定していた場合、距離の短い順番に【A,B,A,C,A,…】となった場合、【未知の文字】は【A】と識別される仕組みです。
※この“距離”は例に挙げた28x28ドット、つまり784次元の空間座標の中での2つのベクトル間の距離を意味します。イメージとして捉えやすいようにそれぞれの文字の特徴空間を2次元空間として表現していますが、実際のOCRアルゴリズム処理の中では数百~数千次元となる多次元空間の座標となります。3次元空間までは容易にイメージすることができますが、それ以上の次元空間となるともはや人間がイメージできるものではありませんね・・・。
kNN法のメリットはアルゴリズムの実装が容易であることが挙げられます。デメリットは対応するフォントの種類が多くなるとフォント毎の特徴となる識別ポイントが曖昧となり誤読する確率が高くなることや、すべての画像データを保存するのに必要なメモリー容量が膨大となるために照合にかかる時間が長くかかってしまうことが挙げられます。
SVM(Support Vector Machine)法|読み取りたい文字の機械学習
SVM法はSupport Vector Machineの略で教師あり学習を用いたパターン認識モデルの1つです。「n次元の特徴量をもつ識別対象を2つのクラスに分類するにあたり、学習対象となった既知の2つのデータ群に対して最大のマージンが得られる境界線(サポートベクトル)を求めることで、【未知の文字】に対しても高い精度の識別が期待できる」手法となります。仮に読み取り可能な文字を【A】・【B】の2つとし、それぞれ※2次元の特徴ベクトルで表現するとします。【A】と【B】、それぞれの特徴ベクトルによって定まる座標はフォントの種類、印字の太り・細り、撮影角度の変化に伴う像の歪みやノイズなどによってばらつきを持ちます。このとき【A】と【B】のデータ群に対し、最大のマージンを得るための境界線をサポートベクトルと呼びます。
※kNNの説明と同じで実際には数十~数百次元の空間座標で定まる座標となります。
OCRでSVM法を利用する場合は、学習のために用意された【A】と【B】それぞれ、フォントや撮影条件、ノイズレベルなどの違いでバリエーションを持たせた複数のサンプル画像を元に機械学習を行い、最大のマージンを得るサポートベクトルを求めます。未学習の文字に対して学習で求められたサポートベクトルを境界としてどちらに分類されるかにより、柔軟かつ高精度な文字の識別を実現します。SVM法は、基本的には2つのクラス(OCRでは文字)を識別するための手法ですが、工夫次第で多クラスの識別も可能になります。
例えば、以下のように3つのSVMを用意します。
イ: 【A】と【B】を比較するSVM
ロ: 【A】と【C】を比較するSVM、
ハ: 【B】と【C】を比較するSVM
【未知の文字】が【C】であったとしたとき、【イ】では【A】と【B】のどちらと識別されるかはっきりしませんが仮に【A】とします。そして【ロ】および【ハ】では、正しく【C】と識別されるでしょう。このように【未知の文字】を3つのSVMで比較した結果、2つのSVMが【未知の文字】を【C】と判定したので、【C】と識別されデータが出力されます。このように読み取り対象文字の数だけSVMを比較することにより、最も可能性の高い文字を決定することができます。
ソロモンOCRではバーコードリーダーという限られたハードウェア・リソースの中でSVMアルゴリズムで処理ができるように計算量を抑えて、実用的な処理時間に収まるように様々な工夫を凝らしています。
ディープ・ラーニング(Deep Learning)法 |読み取りたい文字の機械学習
ディープ・ラーニングの技術は人間の神経細胞(ニューロン)の仕組みを模したシステムで、ニューラルネットワークをベースとして神経細胞を多層にしたものです。AIと同じく最近良く耳にする言葉となりましたが、ディープ・ラーニングの理論は半世紀以上も前から存在していました。近年、この理論を実現するためのハードウェアが実用化されたことと、2012年に様々な物体を撮影した画像の認識率の高さを競うILSVRCにおいて、ジェフリー・ヒントン氏率いるトロント大学のチームが初参加にして圧倒的な成績で勝利したことを機に、世界中でディープ・ラーニングが競って研究されるようになりました。また、同年、Googleがディープ・ラーニングを利用して、“猫”の画像を識別できるAIを発表したことも当時耳にした人もいるかと思います。近年、ディープ・ラーニングが広がった理由としてハードウェアの向上とともに、大量のデータを容易に入手できるようになったことが挙げられます。ディープ・ラーニングは、ニューラルネットワークの層を深くして大量のデータを使って学習することが特徴です。
ディープ・ラーニングの学習は一般にGPU(Graphics Processing Unit)を利用して行われます。本来、GPUは3Dグラフィックスの計算処理に特化して設計されたもので、小規模な演算素子を大量(数千個)に搭載することで、膨大な並列計算を得意とするデバイスです。この特性がディープ・ラーニングの計算にも適しており、かつ、GPUを搭載したグラフィックボードは、コンシューマー向けに大量に量産されることから価格も安いため、広く利用されるようになりました。
ディープ・ラーニングを利用したOCRも実用化されていますがコンピューターの消費電力、必要な計算量やメモリー容量などの点から、とてもバーコードリーダーやハンディーターミナルなどのハンディスキャナーで利用できるようなものではありません。そのためハンディスキャナー向けのOCRとして採用されるのは、主にkNN法あるいはSVM法をベースとしたアルゴリズムとなります。
今後、5G(第5世代移動通信システム)の普及により、スキャナーと処理能力の高いコンピューターを繋ぐことでディープ・ラーニングを利用したハンディスキャナー型OCRが登場する可能性も考えられるでしょう。

この記事を書いた人